A newer version of this content is available on ReWorkflow ReSource.
The Slate API
Does Slate have an API?
We get this question all the time, and the answer is...it's complicated. Slate doesn't offer a pre-defined, monolithic API. Instead, it has tools that allow you to define your own REST-like API's:
- HTTP GET: use Query Builder to define a JSON/XML/Raw web service
- HTTP POST: use Upload Dataset and Source Formats to define a JSON/XML/Delimited web service
The Query Builder is a powerful tool for building SQL queries with a graphical interface; custom SQL is allowed.
Source Formats are a little less user-friendly; you can define the structure of your import with XML or provide a sample Excel file to be automatically parsed. Then you map each source field to its destination, potentially with value mappings.
Both tools default to exporting and importing Excel files but can become web services with a few clicks. Queries can be authenticated or anonymous, but Source Formats require authentication.
How can I get only new rows?
When using Query Builder, you can choose to export all data each time or to export only new data. What's considered "new data" is controlled by the primary key for the particular query. When this option is enabled, each query internally tracks which primary keys have already been returned in a previous query run.
Defining a secondary key will return each unique combination of Row X + Row Y only once, which has many clever uses.
How can I get only changed rows?
There's a system-wide queue for major tables (people, applications) that tracks when each row was last updated. You can set your query to only return rows that have been updated since the last query run. Note that any change to a person or application will cause them to enter the queue - not just the fields on your particular query. For this reason, this option is a little crude.
What happens when I push data to Slate?
The data isn't instantly imported. It enters an upload queue that processes about every 15 minutes. Once imported, the new record you created or existing record you updated enters the aforementioned person/application update queue. As part of this queue, the automation rules will re-evaluate the person/application and potentially make changes. In this way, you can set up rules to do stuff based on your data push.
Are there limits on web services?
There is a web services CPU limit per Slate instance, but it's very high. The most common speed issues are waiting for a Souce Format to ingest data or a poorly-written Query to run.
More Esoteric Options
You can also:
- Configure a Source Format to GET data from a remote endpoint on a schedule.
- Enable JSONP with Query web services.
- Configure a Query to POST to a remote endpoint on a schedule.
- Configure a Query as a Materialized View and refresh is on a schedule (useful for very large, slow queries).
- Use certificate-based authentication and PGP.
- Configure a Query to export to a Source Format (i.e. round trip within Slate). When combined with custom SQL, this allows automation beyond what's possible with the built-in Rules.
- POST data to a Slate Portal custom SQL method and instantly write to the database (Danger, Will Robinson!).
- Import and export SFTP (ick!)
- Import and export PDF's and DIP formats, which is a whole different ball of wax.
Examples
These examples will cover only basic use cases with JSON. Much more information can be found in Slate's own documentation.
GET
GET requests are very easy. Create your query and turn it into a web service with the Edit Web Service button. Then click Edit Permissions and Add Grantee. The most straightfoward grantee type is Username, which allows you to specify a username, password, and token. After saving permissions, click the "JSON" link and select your grantee to get the endpoint URL.
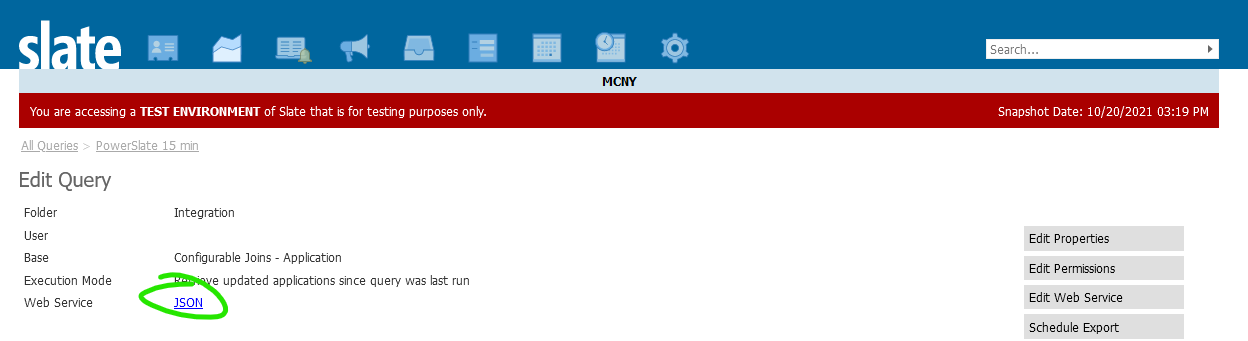
Authentication can be Basic or none. Unauthenticated web services have their place, such as a JSON feed of public events that the school wishes to promote. For an unauthenticated web service, select User Token as the Type under Edit Permissions.
GET Parameters
Click Edit Web Service, then define a parameter with XML. You might define a person ID like this:
<param id="pid" type="uniqueidentifier" />
After defining the parameter, you may use it as @pid in your query filters. Parameter names are arbitrary.
Types are minimally documented; a list can be found here. Parameters are ultimately converted to a .NET System.Data.DbType. If in doubt, don't define a type and it will default to AnsiString.
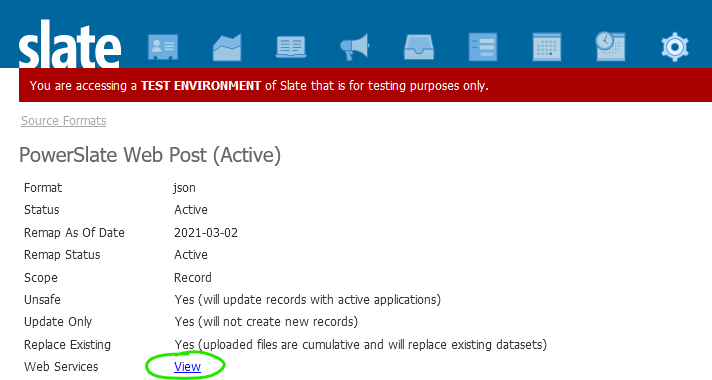
POST
Define a Source Format within Slate, then click the Web Services link to view the endpoint URL. Authentication can be basic or certificate-based. The username and password are not specific to the source format but instead belong to a Slate user account, typically a service user.
The source format needs an XML definition (XPath syntax) that correponds to the JSON body you will send. Example:
<layout type="json" node="/row"> <f id="Application GUID" s="aid" /> <f id="Record Found" s="found" /> <f id="Registered" s="registered" /> <f id="Registered Date" s="reg_date" /> <f id="Withdrawn" s="withdrawn" /> <f id="Registered Credits" s="credits" /> </layout>
A matching JSON request body:
{
"row": [
{
"found": true,
"registered": false,
"withdrawn": false,
"credits": "0.00",
"aid": "0d6d5e78-f89a-4a93-98e1-058aecd5fe93"
},
{
"found": true,
"registered": true,
"reg_date": "2021-04-07",
"withdrawn": false,
"credits": "12.00",
"aid": "0425e15a-6c55-4c3c-9e83-d9b9d40cbacf"
}
]
}
As usual with Source Formats in Slate, you must click Remap and define mappings between your external source columns and internal destinations.
More on Source Format XML Definitions
Nested dicts in JSON or XML are possible but beyond the scope of this article.
You might wonder why the JSON has a root element of "row." We believe that Slate converts JSON to XML internally using Newtonsoft.Json.ConvertersXmlNodeConverter. However, XML doesn't have simple arrays like JSON. Therefore, you must supply an outer element name that will become the root element when the JSON array is converted to XML.
Still confused? See this post, or try an online JSON to XML converter and compare the XML versions of the following:
[
{
"aid": "15454d71-0378-4b23-bea2-6e854a53c2b5",
"people_code_id": "**********",
"credits": "12.0",
"registered": "True"
},
{
"aid": "a2bd4535-c8f8-4417-b91a-0cf7c406ac37",
"people_code_id": "**********",
"credits": "0",
"registered": "False"
}
]
Vs
{
"row": [
{
"aid": "15454d71-0378-4b23-bea2-6e854a53c2b5",
"people_code_id": "**********",
"credits": "12.0",
"registered": "True"
},
{
"aid": "a2bd4535-c8f8-4417-b91a-0cf7c406ac37",
"people_code_id": "**********",
"credits": "0",
"registered": "False"
}
]
}